Vous avez peut-être déjà entendu cette maxime, qui insiste sur le fait que corrélation n’implique pas toujours causalité. On va explorer ici les multiples cas de figure où une corrélation peut être observée sans qu’il n’y ait absolument aucun lien de causalité sous-jacent.
Cas de figure 1 : la pure coïncidence.
En statistiques, si on apprend un truc, c’est que quand on cherche… on trouve. Lorsque l’on fait des statistiques dans tous les sens, il y a une infinité de combinaisons possibles, si bien que par pure coïncidence, on puisse trouver des corrélations totalement fortuites. A tel point qu’un site, Spurious corrélations, s’est donné pour mission de répertorier les corrélations les plus absurdes. Par exemple, cette corrélation entre la consommation de margarine et le taux de divorce dans l’état du Maine, aux USA. Pour commencer à suspecter un lien de cause à effet lorsqu’il y a une corrélation, la première exigence, c’est d’avoir, a priori, des raisons logiques de penser qu’il puisse y avoir un lien de cause à effet. La seconde, c’est qu’un pattern devrait se retrouver dans différents contextes sans trop d’altération. Ici, les données sont réduites à l’état du Maine, et il est probable que si on regardait la corrélation dans d’autres états… on ne la retrouverait pas.

Cas de figure 2 : une cause commune
Imaginons, vous tombez sur un article qui montre qu’il y a une corrélation entre le fait d’être en surpoids et le risque de maladies cardiaques. Cela fait sens. Le surpoids consiste en l’accumulation de graisses, et ce sont les acides gras qui provoquent des accidents cardiaques. Cependant, une telle corrélation pourrait tout aussi bien être due au schéma suivant :

Si tel était le cas, une thérapie qui consisterait à perdre du poids n’aurait aucune incidence sur les maladies cardiaques, car elle n’agirait pas sur la cause réelle des maladies cardiaques : la musculation du coeur. Pour inférer un lien de causalité entre le poids et les maladies cardiaques, dans ce cas, il va être nécessaire de « stratifier » l’échantillon d’étude. Il faudra faire plusieurs groupes d’individus en fonction du degré de musculation du cœur, et regarder si la corrélation entre le poids et l’occurrence des maladies cardiaque persiste… à l’intérieur de chacun de ses groupes. En effet, à l’intérieur de chaque groupe, tout le monde ayant la même musculature cardiaque, les différences qui seraient observées seraient réellement liées au poids. Et il est tout à fait possible que les deux variables aient un effet, évidemment.
Cas de figure 3 : ce n’est pas A qui cause B, mais B qui cause A (causalité inversée).
Imaginons que les femmes soient (en moyenne) moins payées que les hommes, et qu’en cherchant à décomposer les causes de cette différence, on se rende compte que les femmes occupent plus souvent des emplois moins bien payés que les hommes. On pourrait s’empresser de conclure que les femmes gagnent moins que les hommes parce qu’elles choisissent des emplois moins bien rémunérés. Mais ce serait oublier que la causalité peut tout aussi bien être inversée : les emplois plus souvent occupés par les femmes auraient une rémunération moyenne inférieure aux emplois plus souvent occupés par les hommes, parce que les femmes sont discriminées.

Cas de figure 4 : la causalité sans corrélation
Pour terminer, un petit cas particulier. Peut-il y avoir un lien de causalité sans qu’on ait mesuré de corrélation ? Et bien même si c’est improbable, ce n’est pas impossible. Imaginez que vous compariez l’efficacité de deux traitements, A et B, sur une maladie. Vous ne trouvez aucun effet, l’efficacité comparée des deux traitements est identique, et vous publiez donc votre résultat dans le Journal of null results :
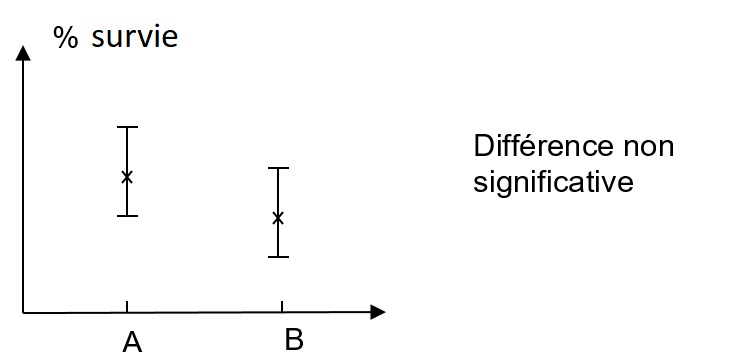
Peu de temps après la publication, il y a votre pote Julie, qui est chimiste, qui a lu votre publi et qui vous dit : « hé j’ai vu ta publi, mais tu sais que A et B sont des molécules qui interagissent avec la caféine ? Tu devrais contrôler cette variable quand même ». Du coup, vous interrogez un peu vos patients, vous ré analysez les données, et là, que trouvez-vous ?

Tadaaam. Vous trouvez que le traitement A est plus efficace chez les patients qui boivent du café, et B plus efficace chez les patients qui n’en boivent pas. Si on fait la moyenne des groupes en considérant qu’il y a à peu près autant de buveurs de café que de non buveurs de café, on retombe à peu près sur le graphe ci-dessus.
Alors, je parle de ce cas particulier, qui est assez improbable, parce que je l’ai déjà vu apparaitre chez des tenants de « médecines alternatives» (enfin, c’est rare, mais chez les plus malins), pour défendre l’idée que leur médecine fonctionne, mais que ça se voit pas dans les statistiques, parce que « ça dépends des individus ». Alors, oui, c’est une possibilité c’est vrai. Mais le truc, c’est que tant qu’on sait pas « de quelle manière ça dépends des individus », et bien…. ça sert à rien. Si je donne A et B aux individus sans savoir que A marche mieux pour certains et B pour d’autres parce que les uns boivent du café et d’autres pas, alors mon résultat, c’est le graphe du dessus : ça marche pas mieux avec un traitement que l’autre. Du coup, si jamais ils ont une idée claire de la raison pour laquelle leur médecine alternative n’est pas ‘statistiquement’ plus efficace qu’un placebo, mais qu’elle peut être efficace pour certains individus en particulier, alors c’est très simple : j’invite ces tenants à mettre en place un protocole qui teste l’efficacité de la médecine alternative en question en contrôlant explicitement la caractéristique des individus qu’ils utilisent comme indicateur de l’efficacité probable de cette médecine pour ces individus. Si ça marche, vous serez célèbres.
Comment s’assurer qu’une corrélation correspond à un lien de causalité?
Et bien, il y a quelques critères à vérifier, notamment :
– La temporalité (A se produit avant B).
– La plausibilité (explication mécanique / coherence logique: ex la mutation kdr-R qui code l’allèle de résistance aux insecticides, pourrait générer un cout physiologique tel que le moustique dispose de moins de ressources pour lutter contre le parasite et pourrait être plus souvent infecté, donc je m’attends à observer une possible corrélation entre la présence de ce gène et le taux d’infection).
– Gradient biologique (Plus de A correspond à plus de B: ex les hétérozygotes kdr-R/kdr-S sont moins infectés que les homozygotes kdr-R/kdr-R et plus infectés que les homozygotes kdr-S/kdr-S).
– Consistance / pouvoir prédictif: le lien entre A et B est retrouvé dans de nombreux contexts et de nombreuses conditions (e.g. dans de nombreux sites d’étude ou populations)
– Dégré de l’association ( / ou corrélation), taille d’effet élevée.
– Spécificité: B est rarement trouvé sans A (mais souvenez vous que si A ->B, B peut aussi avoir plusieurs causes)
– Préventabilité (test experimental : le gold standard): si A est supprimé, B disparait.
Si vous voulez un récap sur les différents niveaux de preuve et les études qui permettent de les obtenir, n’hésitez pas à relire cet autre billet.
Voilà, ce billet se sera fait attendre, mais c’est fait ! J’espère que vous aurez aimé.
Article originellement publié le 18 nov. 2017, republié le 07 mars 2018 suite à migration du site.
Article reproduit avec l’aimable autorisation de l’autrice, publié originellement sur Ce n’est qu’une théorie